Programming in C and first principles
September 8, 2024

Introduction
Programming languages are tools, each offering unique benefits. While I've written C in the past for coursework, I haven't used it professionally. Recently, I've developed an interesting urge to learn it more deeply as my interest in low-level computing systems continues to grow.
Learning a new programming language is about developing a new mental model. It can be challenging to develop this new mental model when the language differs significantly from those you're familiar with. For instance, coming from Go, C might seem easier to reason about initially. However, C presents its own set of challenges and concepts that require careful consideration.
One of the most interesting aspects of C is its close relationship with the hardware, concepts like manual memory management, pointers, and direct manipulation of memory addresses offer a level of control that's both powerful and potentially daunting. These features, while they maybe complex, provide a unique window into how computers actually work at a fundamental level. In fact, while working with C on Linux, most of the essentials for writing, compiling, and executing programs are already available out of the box.
First Principles ?
When learning a new programming language, I find it valuable to approach it through first principles. This method allows me to reason about the language more effectively and develop a new mental model that can adapt to the language's unique syntax and concepts. Let's examine some of the six(6) fundamentals that guide my thought process:
- Data representation and transformation: Understanding how to manipulate data at its most basic level, including operations like byte manipulation, base64 representation, encoding, and decoding. Example of questions we may ask ourselves is: how do i represent money value or how do i transform this data into something else (something smaller like compression)
- Persist & Read Data (filesystem): Grasping methods for storing and retrieving data, including file operations (write, read) & system calls.
- Data Transport (socket): Comprehending how to move raw data between systems over networks, focusing on socket programming, data reception, and read/write operations.
- Organize data (data structures ): Mastering essential structures such as queues, stacks, binary heaps, and tries e.t.c, which form the building blocks of efficient algorithms and programs.
- Computer data (algorithms): Exploring various algorithms and methods to process and analyze data effectively e.g sorting e.t.c.
- Managing & execute tasks (concurrency and parallelism): Understanding threads and futures to leverage multi-core processors and manage asynchronous operations efficiently.
First principles flowchart:
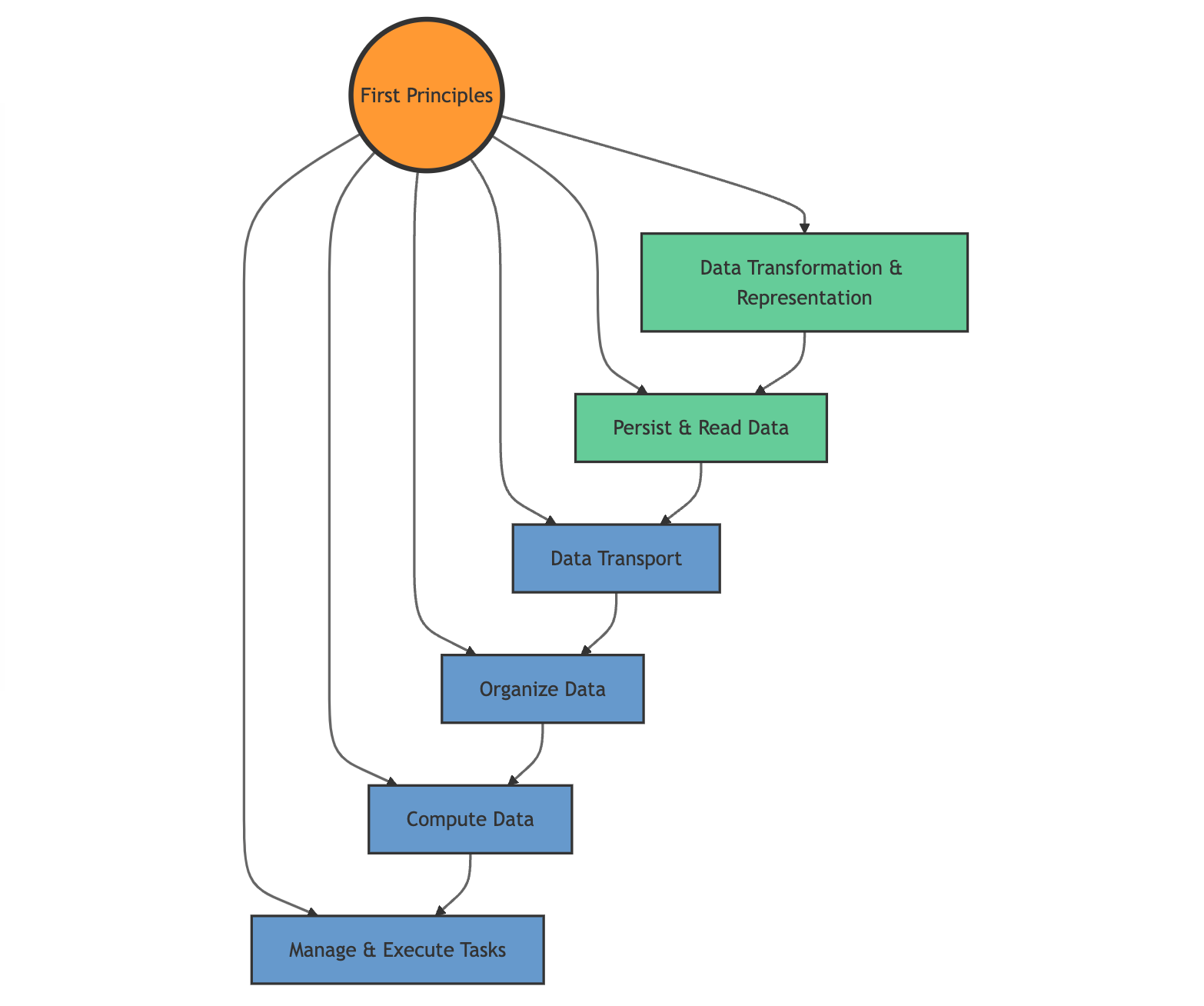
First principles flowchart
If you dig deeper, these are the basic building blocks of most programming languages, and mastering them is your first step towards understanding the language. In fact, you can quickly get your hands dirty by focusing deeply on just these fundamentals, iterating and experimenting until the syntax and language paradigms stick and you can use them effortlessly. The rest you can always Google as needed. In this article , I am going to explore a part of these principles with more focus on the language syntax.
What is C?
C is a system programming language designed for building low-level programs. It's used for developing kernels, networking tools (like TCP implementations and sockets), and both single-threaded and multi-threaded programs, among many other applications (redis, nginx , linux kernel etc)
Getting started:
before we begin, every c file starts with main . This is the entry point of our program and in order to use functions from C's standard libraries (or other libraries), we need to include them at the beginning of our program. This is done using the #include directive.
#include <stdio.h> // Include the standard input/output library
/**
* @brief The main function - entry point of the program
* @return 0 on successful execution
*/
int main() {
// Your code goes here
return 0; // Indicate successful program execution
}
Data Types:
Data types form the foundation upon which everything in programming is built, from char, int, and float to double and boolean. Every programming language relies on these fundamental data types. By defining a data type, we're essentially telling the compiler, "Hey, I'm trying to store this specific type of data and nothing else."
If you've written JavaScript in the past, you'll understand how error-prone programs can be without strict data types. Without them, you often end up with code behaving unpredictably.
Basic Datatype Examples:
#include <stdio.h>
#include <stdbool.h>
int main() {
// Integer declaration
int num = 42;
// Character declaration
char letter = 'A';
// String Variables as Arrays declaration
// using array allows us to mutate specific index within the string.
char string[50] = "Hello, world!";
// allow the comipler to figure out the length
char s[] = "Hello, world!";
// String Variables
char *s = "Hello, world!";
// Float declaration
float pi = 3.14159f;
// Double declaration
double large_number = 123456.789012;
// Boolean declaration
_Bool is_true = 1;
// Or you we use <stdbool.h>
bool is_value_true = true;
// Printing values to demonstrate
printf("Integer: %d\n", num);
printf("Character: %c\n", letter);
printf("String: %s\n", string);
printf("Float: %f\n", pi);
printf("Double: %lf\n", large_number);
printf("Boolean: %d\n", is_true);
return 0;
}
Array:
Declaring an array in C can be done using square brackets. When we declare an array, we have to give it a size and the size has to be fixed. below we specify that we want to store 100 integers in the array:
int numbers[100];Basic syntax:
#include <stdio.h>
int main() {
int numbers[] = {1, 2, 3, 4, 5};
for (int i = 0; i < 5; i++) {
printf("%d ", numbers[i]);
}
return 0;
}Structs in C:
Structs in C are user-defined data types that allow you to group related data elements together. They are fundamental to organizing and manipulating complex data in C programs.
Basic syntax:
struct Point {
int x;
int y;
};Nested Struct:
struct Rectangle {
struct Point top_left;
struct Point bottom_right;
};Usage:
#include <stdio.h>
int main() {
struct point point_1 = {10, 20};
struct point point_2 = {10, 20};
struct rectangle rect = {{0, 0}, {50, 70}};
printf("Point_1: (%d, %d)\n", point_1.x, point_1.y);
printf("Point_2: (%d, %d)\n", point_2.x, point_2.y);
return 0;
};
Dynamic Memory
malloc ,calloc , free and realloc are used for dynamic memory allocation in C. This allows programmers to efficiently manage memory and free it when they're done using it. If you're familiar with Go, it has a garbage collector that periodically frees memory based on sophisticated algorithms. In Rust, memory management is achieved through the use of ownership principles.
One important aspect in C is that when you declare a pointer to a struct, accessing or modifying its members can be done using the arrow(->) operator or by dereferencing the pointer and using the dot(.) operator. For example:
// using arrow operator
struct_ptr->member
// which is equivalent to
(*struct_ptr).memberMore sophisticated example:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
struct User {
char name[50];
int age;
};
int main() {
// Dynamic allocation for struct
struct User *ptr_user = (struct User*)malloc(sizeof(struct User));
if( ptr_user == NULL) {
fprintf(stderr, "[ERR] Memory allocation failed");
return 1;
}
strcpy(ptr_user->name, "John Doe");
ptr_user->age = 30;
printf("User: %s, %d years old\n", ptr_user->name, ptr_user->age);
free(ptr_user);
return 0;
}
Array:
An interesting observation is that dynamic memory allocation follows a similar pattern across different data types. For arrays, you simply need to tell the compiler, "Hey, create space for a certain number of elements for me."
For example:
int *dynamic_array = (int*)malloc(5 * sizeof(int));The key difference in the above code is the number 5. We're essentially instructing the compiler to allocate space for 5 integers in an array. If we remove the 5, just like we did in the example below, we're telling the compiler to allocate space for just one integer:
int *int_ptr = (int*)malloc(sizeof(int));Array Example:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main() {
// Dynamic allocation for array
int *ptr_dynamic_array = (int*)malloc(5 * sizeof(int));
if (ptr_dynamic_array != NULL) {
for (int i = 0; i < 5; i++) {
ptr_dynamic_array[i]= i + 1;
}
free(ptr_dynamic_array);
}
return 0;
}Others:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main() {
// Integer
int *int_ptr = (int*)malloc(sizeof(int));
*int_ptr = 42;
printf("Integer: %d\n", *int_ptr);
free(int_ptr);
// Character array (string)
char *str_ptr = (char*)malloc(20 * sizeof(char));
strcpy(str_ptr, "Hello, World!");
printf("String: %s\n", str_ptr);
free(str_ptr);
// Float
float *float_ptr = (float*)malloc(sizeof(float));
*float_ptr = 3.14;
printf("Float: %.2f\n", *float_ptr);
free(float_ptr);
return 0;
}
Pointers:
Pointers are a fundamental concept in C that allows us to work directly with memory addresses. They're powerful tools that enable efficient memory management and complex data structures. Below is a basic overview of pointers.
Declaring a pointer:
int *int_ptr;Address-of operator: We use the & symbol to get the address of a variable
int x = 0; // set x = 0
ptr = &c;Dereferencing: We can access the value at the address a pointer holds by using the ******* symbol:
int y = *ptr; // y now equals 10
printf("Pointer value: %d", y); // Result: Pointer value: 10
Modify a pointer:
*ptr = 20; // This changes the value of x
printf("New value of x: %d\n", x); // Result: New value of x: 20
Another example:
variable x, is initialized with an address to a pointer y and y is initialized with an address to pointer k
int x = 10; // x is an integer variable
int *y = &x; // y is a pointer to an integer, initialized with the address of x
int **k = &y; // k is a pointer to a pointer to an integer, initialized with the address of y
File I/O Operations:
Here we try to open a file called example.txt and write to it. We close the file using fclose immediately after we're done to prevent corrupting the file or holding onto the file pointer unnecessarily. By using fclose, we're telling the compiler to free the memory associated with the file operation.
Writing to a File:
Opens "example.txt" in write mode, writes a message, and closes the file.
FILE *file = fopen("example.txt", "w");
if (file == NULL) {
fprintf(stderr, "[ERR] Error opening file");
return 1;
}
fprintf(file, "Hello, File I/O!"); // WRITE to the file
fprintf(stdout,"File successfully written.\n");
fclose(file); // CLOSE the file
Reading from a File:
Opens the file in read mode, reads content line by line using fgets()
char buffer[100]; // Memory location to temporarily store data read from the file
file = fopen("example.txt", "r");
if (file == NULL) {
fprintf(stderr, "[ERR] Error opening file for reading");
return 1;
}
int line_number = 0;
while (fgets(buffer, sizeof(buffer), file) != NULL) {
line_number++;
fprintf(stdout, "[Line %d]: %s", line_number, buffer);
}
fclose(file); // CLOSE
Appending to a File:
Opens the file in append mode, adds new text to the end of the file, and closes it. Appending preserves existing content.
file = fopen("example.txt", "a");
if (file == NULL) {
fprintf(stderr, "[ERR] Error opening file for appending");
return 1;
}
fprintf(file, "This is appended text.\n");
fclose(file);
Socket
Socket programming is one of the most fun stuff in C. It enables client-to-server interactions using protocols like TCP and UDP, allowing crucial the development of networked applications, from simple chat programs to complex distributed systems.
Client-To-Server interaction flowchart:
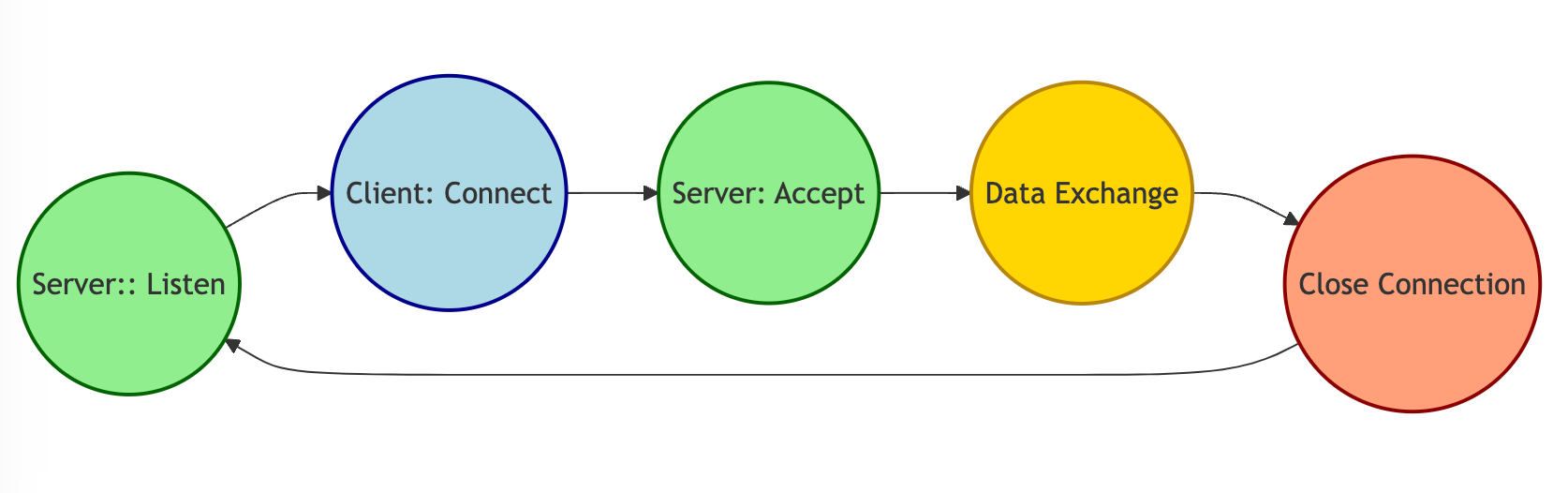
Client-To-Server interaction flowchart
Note: In socket programming, sockets are treated like files (following Unix's 'everything is a file' philosophy). This is why most C socket code uses server_fd, known as the server file descriptor, which is an identifier for the socket. The term 'file descriptor' might seem unusual compared to 'ID', but it's the standard terminology in Unix-like systems, reflecting the treatment of sockets as a type of file
Stage 1: C Socket Creation:
int server_fd;
if ((server_fd = socket(AF_INET6, SOCK_STREAM, 0)) < 0) {
fprintf(stderr, "[ERR] unable to create socker file descriptor");
exit(1);
}The socket() function is used to create a new socket. It takes three parameters:
AF_INET6: This is the address family. It specifies that we're using IPv6. If we wanted to use IPv4, we would useAF_INETinstead.SOCK_STREAM: This specifies the type of socket.SOCK_STREAMindicates that we want a TCP socket, which provides reliable, stream-oriented connections. If we wanted UDP, we would useSOCK_DGRAM.0: This is the protocol. Passing 0 here lets the system choose the most appropriate protocol for the given address family and socket type. For TCP, this will be the TCP protocol.
The function returns a file descriptor (server_fd) that we'll use to refer to this socket in later operations.
Stage 2: Setting C Socket Options:
int opt = 1;
if (setsockopt(server_fd, SOL_SOCKET, SO_REUSEADDR, &opt, sizeof(opt))) {
fprintf(stderr, "[ERR] unable to set socket options");
exit(1);
}The setsockopt() function is used to set options on the socket. Let's break down its parameters:
server_fd: This is the socket file descriptor we just created.SOL_SOCKET: This specifies that we're setting a socket-level option.SO_REUSEADDR: It allows reuse of local addresses. This is useful when we want to restart our server quickly after it exits. Without this option, we might have to wait for the system to release the address before we can bind to it again.&opt: This is a pointer to the value we're setting the option to. In this case, we're setting it to 1, which enables the option.sizeof(opt): This is the size of the value we're passing, this is one of the weird things in c, most methods requires "sizeof of something" parameter.
Stage 3: Preparing the Address Structure:
struct sockaddr_in6 address;
memset(&address, 0, sizeof(address));
address.sin6_family = AF_INET6;
address.sin6_port = htons(portno);
address.sin6_addr = in6addr_any;This prepares the address structure for binding:
- We use
memset()to zero out the structure, ensuring there's no garbage data. - We set the address family to
AF_INET6for IPv6. - We set the port using
htons()to convert the port number to network byte order. - We set the address to
in6addr_any, which allows the socket to bind to all available IPv6 interfaces.
Stage 4: Binding the Socket:
if (bind(server_fd, (struct sockaddr*)&address, sizeof(address)) < 0) {
fprintf(stderr, "[ERR] unable to bind ");
exit(1);
}The bind() function associates the socket with a specific address and port:
server_fd: it is our socket file descriptor.(struct sockaddr*)&address: it is a pointer to our prepared address structure, cast to a generic socket address structure.sizeof(address): is the size of our address structure.
Stage 5: Listening for Connections:
if (listen(server_fd, maxnpending) < 0) {
fprintf(stderr, "[ERR] unable to start listener");
exit(1);
}The listen() function marks the socket as passive, meaning it will be used to accept incoming connection requests:
server_fd: Our socket file descriptor.maxnpending: specifies the maximum length of the queue of pending connections.
Stage 6: Accepting Connections:
int sock_client;
socklen_t socklen = sizeof(address);
if ((sock_client = accept(server_fd, (struct sockaddr*)&address, &socklen)) < 0) {
fprintf(stderr, "unable to accept connection");
exit(1);
}The accept() function is used to accept a new connection on a listening socket. Let's break down its parameters:
server_fd: This is our listening socket file descriptor.(struct sockaddr*)&address: This is a pointer to a structure where the address of the connecting client will be stored. Afteraccept()returns, this structure will contain the client's address information.&socklen: This is a pointer to the size of the address structure. It's both an input and output parameter. On input, it should be set to the size of the address structure. On output, it will contain the actual size of the address.
The accept() function returns a new socket file descriptor (sock_client) for the newly established connection. This new socket is used for communication with this specific client.
Stage 7: Reading Data:
ssize_t bytes_recv;
char buffer[BUFSIZE];
while ((bytes_recv = recv(sock_client, buffer, BUFSIZE - 1, 0)) > 0) {
buffer[bytes_recv] = '\0';
fprintf(stdout, "%s \n", buffer);
send(sock_client, buffer, bytes_recv, 0);
}The recv() function is used to receive data from a connected socket. Let's break down its parameters:
sock_client: This is the socket file descriptor returned byaccept(), representing the connection to a specific client.buffer: This is a pointer to the buffer where the received data will be stored.BUFSIZE - 1: This is the maximum number of bytes to receive. We useBUFSIZE - 1to leave room for a null terminator if we're receiving string data.0: These are flags that modify the behavior ofrecv(). In this case, no special flags are set.
These two functions, accept() and recv(), are crucial for handling incoming connections and data in a server application. accept() allows the server to handle multiple clients by creating new sockets for each connection, while recv() allows the server to read data sent by the client on these connections. Without looking at this code, try to combine the stages for form a simple echo server.
C's abstraction layers:
- C has No Runtime: Unlike Go, C doesn't have a runtime that manages things like garbage collection or goroutines. You're closer to the metal.
- Direct System Calls: In C, you can make system calls directly, though it's more common to use library functions that wrap these calls.
- Manual Memory Management: C requires manual memory allocation and deallocation, which can make network programming more complex and error-prone.
- POSIX Standardization: The POSIX standard provides a consistent API across Unix-like systems, improving portability.
- Lower-Level Control: C gives us more direct control over low-level details, which can be both an advantage (for optimization) and a challenge (for complexity).
C abstraction flowchart
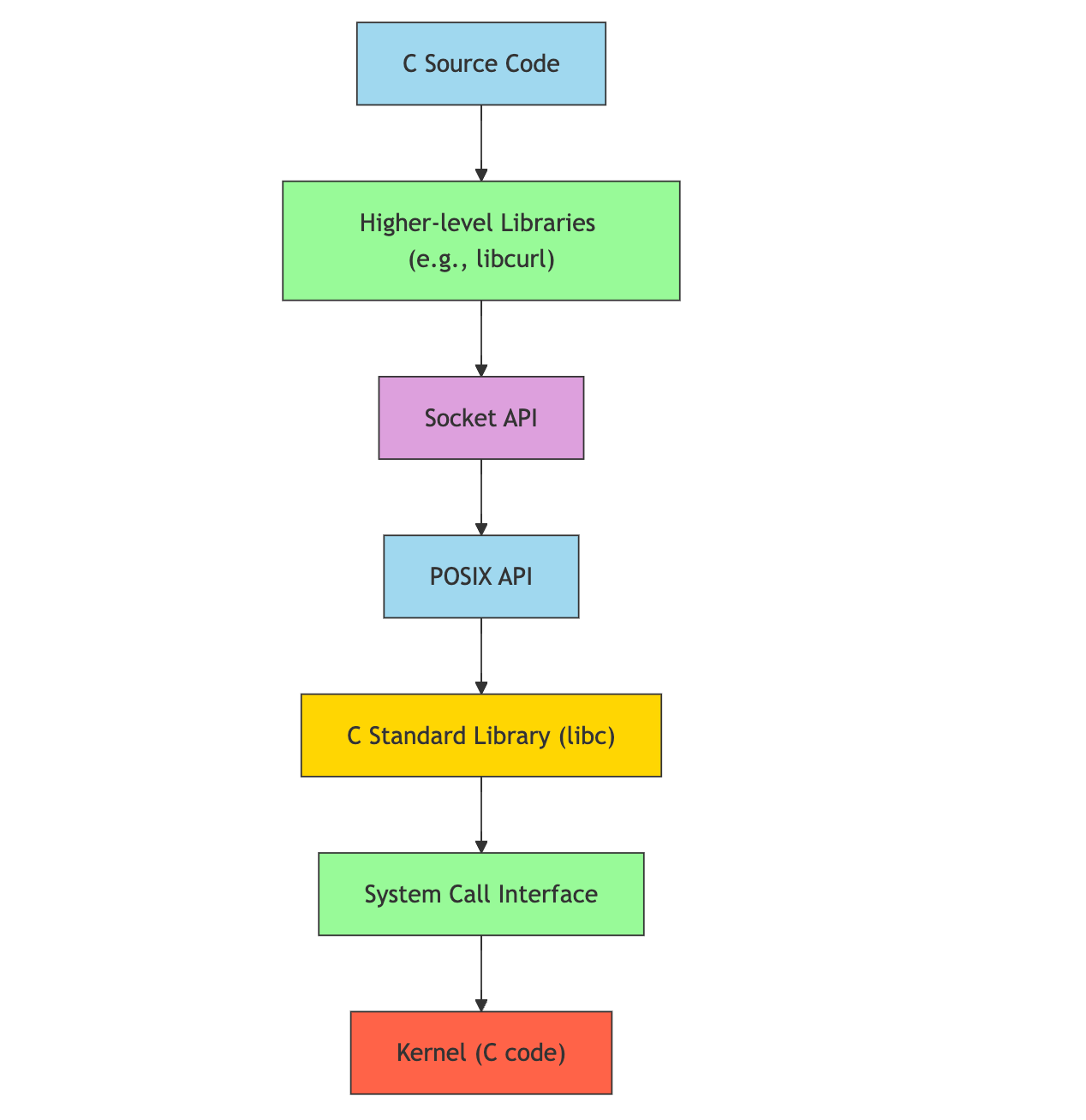
C abstraction flowchart
Rust abstraction flow:
What did you notice as compared to C? With C, we can basically interact with the system kernel via the system call interface directly in our C code. This is possible because most kernels in use today are written in C. For other programming languages like Rust and Go, we need a layer before it in order to execute system calls. For example, in Rust, we use LLVM to generate machine code that we can execute to perform some system calls. C's close relationship with the kernel allows for more direct system interactions because C is close to "bare metal".
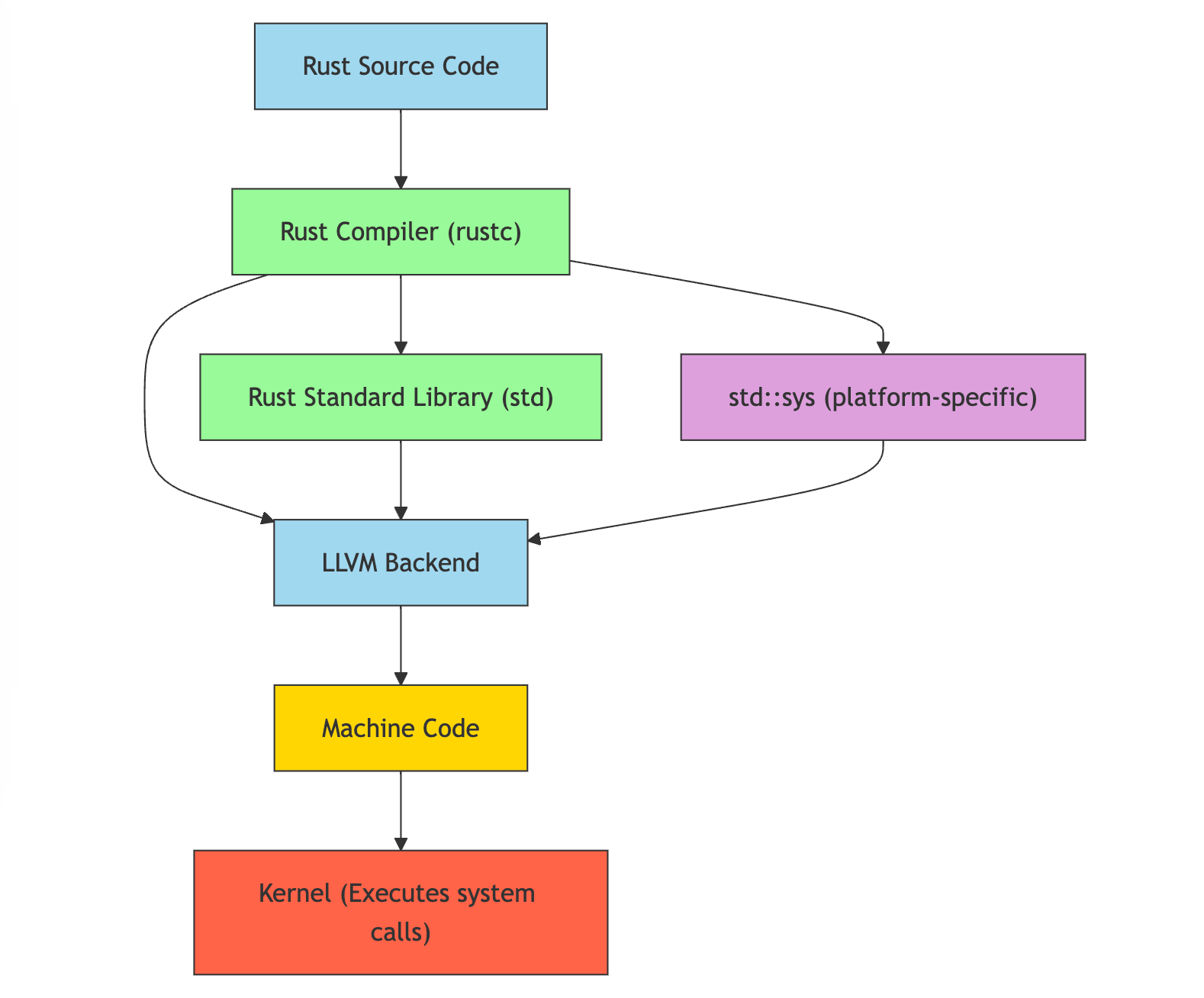
Rust abstraction flow