SWIM — A Scalable Membership Protocol for Distributed System
August 18, 2024
Introduction
SWIM (Scalable Weakly-consistent Infection-style Process Group Membership Protocol) is a protocol designed for managing membership in distributed systems. This article explores the mechanics and implementation of SWIM, focusing on how it helps maintain an up-to-date view of active nodes in a distributed environment, which is crucial for effective communication and coordination among nodes.
Stepping back a second, why are we talking about this? [Feel free to skip]
This was supposed to be another experiment out of curiosity, learning more about distributed systems while studying the DynamoDB paper, but it turned into building a full-blown SWIM protocol written in Rust called Gossipod. At the point of writing this article, I’d completed the paper, read a bunch of stuff online, and watched some videos. When I thoroughly understood the protocol, I explored various implementations online. I was genuinely impressed by the diverse approaches different libraries took to implement SWIM, with HashiCorp’s memberlist being the most impressive one, each filled with interesting ideas and approaches to the internal workings of SWIM.
I decided to write an article and hack on existing implementations. While doing this was fun, I felt it could be even more fun if I built my own. What began as a fun learning exercise evolved into an exciting project, and I’m really excited to publish this article to share my understanding of how SWIM works, with a partial completion of the library. This way, I’m solidifying my understanding and hopefully helping you understand it better too. This journey was challenging but rewarding, giving me a glimpse into the Rust ecosystem (concurrency & performance).
The whole purpose was to analyze the SWIM protocol from first principles, diving deep into its foundations and inner workings. To achieve this, I focused on:
- Foundational concepts and design principles of SWIM
- Protocol mechanics and formal analysis
- Practical implementation and experimentation
Into the details
The term SWIM means Scalable Weakly-consistent Infection-style Process Group Membership Protocol. In a distributed or decentralized environment, communication is a core part of how systems interact with each other. We want systems to coordinate efficiently, creating the illusion of a single cohesive system. Gossip protocols facilitate this by allowing nodes to communicate with each other in a manner similar to how gossip spreads among people.
To illustrate, consider how fake news propagates in real life. Before we realize it, this information has traveled widely, from one user’s timeline across different countries, much like a contagious disease. Gossip protocols in distributed systems work similarly—nodes spread information about themselves and other nodes they’ve communicated with or come into contact with, until all nodes are aware of the system’s state.
Evolution from Traditional Heartbeat Mechanisms
Historically, distributed systems relied on a heartbeat approach for node status monitoring. In this model, each node would broadcast its status to all other nodes in the cluster at fixed intervals, as defined by the system configuration. Each heartbeat is multicasted to all other group members. This results in a network load of O(n²) messages per second (even if IP multicast is used), where n is the number of nodes in the cluster. However, this method quickly became a bottleneck as systems scaled, leading to issues including:
- Scalability: For large-scale systems, the number of status messages grew quadratically with the number of nodes. In a cluster of 1,000 nodes, this could result in millions of messages being sent every few milliseconds, creating a significant network burden.
- Performance Bottlenecks: As the cluster size increased, the volume of heartbeat messages could overwhelm network resources, potentially impacting the system’s primary functions.
- Resource Inefficiency: The constant broadcasting of status updates, regardless of whether changes had occurred, led to unnecessary resource consumption.
SWIM addresses these challenges by introducing a gossip-based protocol that significantly reduces network overhead while maintaining system-wide awareness. This approach allows distributed systems to scale efficiently, supporting thousands of nodes without relying on a central coordinator or compromising consistency.
Key Properties:
- Scalable: The protocol can efficiently handle communication among thousands of nodes, scaling incrementally as the system grows.
- Weakly-consistent: At any given moment, individual nodes may not have a complete, up-to-date view of the entire system. However, the protocol ensures that the system eventually converges to a consistent state.
- Infection-style: Information propagates rapidly through the network, similar to how a highly contagious disease like COVID-19 spreads among a population.
- Process Group Membership: SWIM manages which nodes are part of the distributed system, tracking their status and facilitating communication between them.
Low-level and High-level Communication in SWIM:
SWIM protocol operates at a high level, similar to other distributed systems protocols. However, its implementation relies on low-level network primitives.
High-level design: According to the original SWIM paper, the protocol primarily uses UDP for its core operations. UDP is essential for sending information quickly, which is crucial for SWIM’s gossip-based approach and rapid failure detection. This aligns with SWIM’s high-level goals of scalability and eventual consistency in large distributed systems.
Low-level implementation: At the low level, SWIM leverages UDP’s connectionless nature. While this can lead to packet loss over time, it’s a trade-off SWIM makes for speed and scalability. UDP’s lightweight nature allows SWIM to efficiently manage membership in large-scale systems without overwhelming network resources.
Hybrid approach in modern implementations: Subsequent implementations of SWIM have sometimes incorporated TCP for scenarios where information is critical and must be reliably delivered. Unlike UDP, TCP allows for two-way connections, creating a stream through which information can be sent and responses received, establishing a bidirectional communication channel.
This hybrid approach in modern SWIM implementations leverages the strengths of both protocols:
- UDP is used for frequent, lightweight membership updates and failure detection, aligning with SWIM’s need for speed and scalability.
- TCP might be employed for operations requiring guaranteed delivery or larger data transfers, such as initial state synchronization or critical updates that cannot afford to be lost.
By utilizing both UDP and TCP where appropriate, implementations can balance the need for rapid information dissemination with the requirement for reliability in critical information exchange.
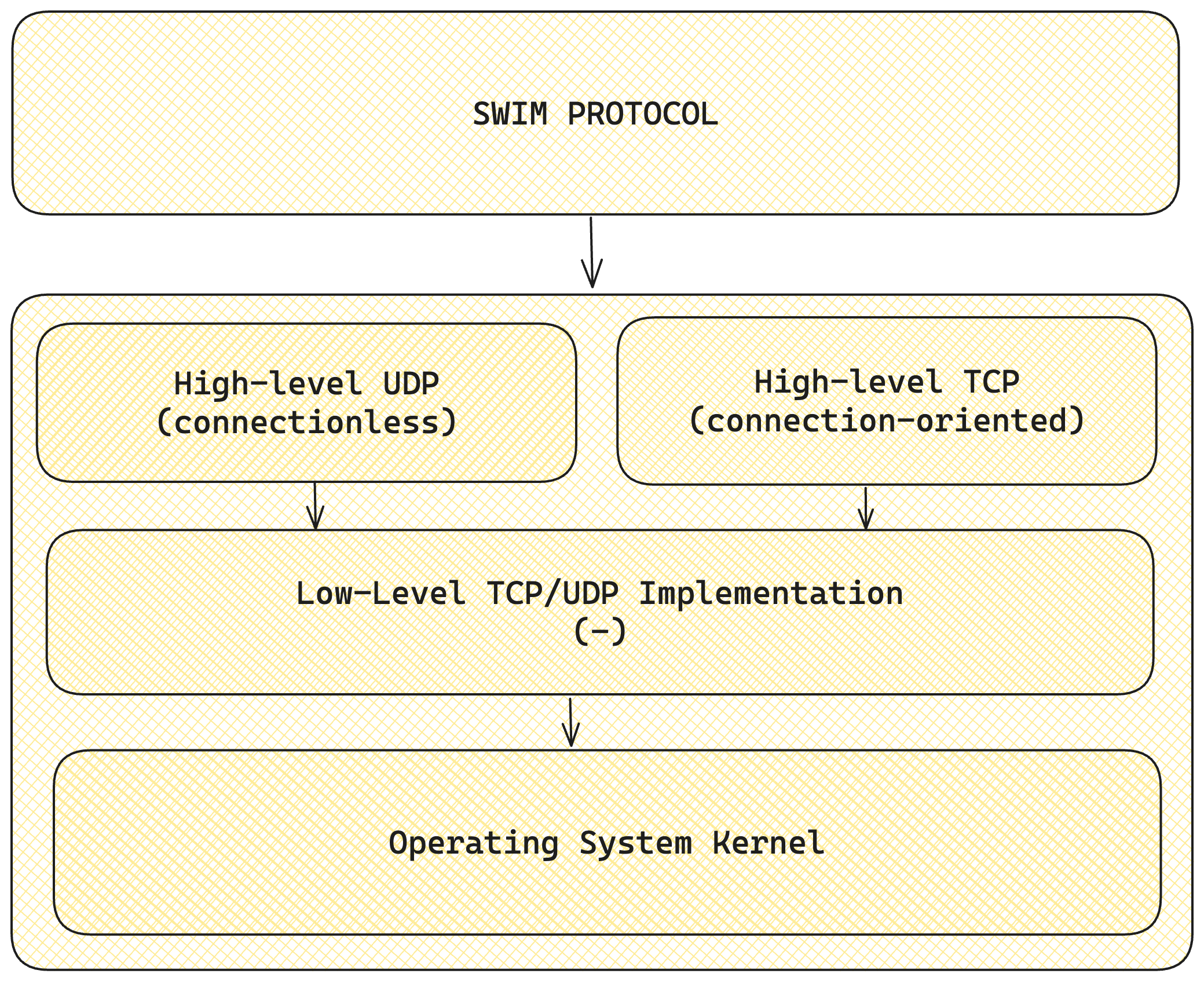
Low-level and high-level communication in SWIM
The SWIM protocol consists of two main components:
Failure Detector
This component is responsible for detecting node failures. It employs both DIRECT and INDIRECT probing mechanisms to assess the status of nodes.
1. Operation:
- A node randomly selects and probes another node in the cluster using round-robin
- The probing node expects to receive an acknowledgment (ACK) message in response within a stipulated interval (timeframe). This is necessary because UDP is connectionless, and there is no reliable way to detect if a node is down except through an ACK response.
- If no ACK is received:
- The probing node initiates an indirect probe.
- It attempts to reach the target node through intermediary nodes.
2. Outcomes:
- If an ACK is eventually received (directly or indirectly), the target node is considered ALIVE.
- If no ACK is received after both direct and indirect probing, the target node is marked as suspected of failure before moving the node to a failed state after a timeout.
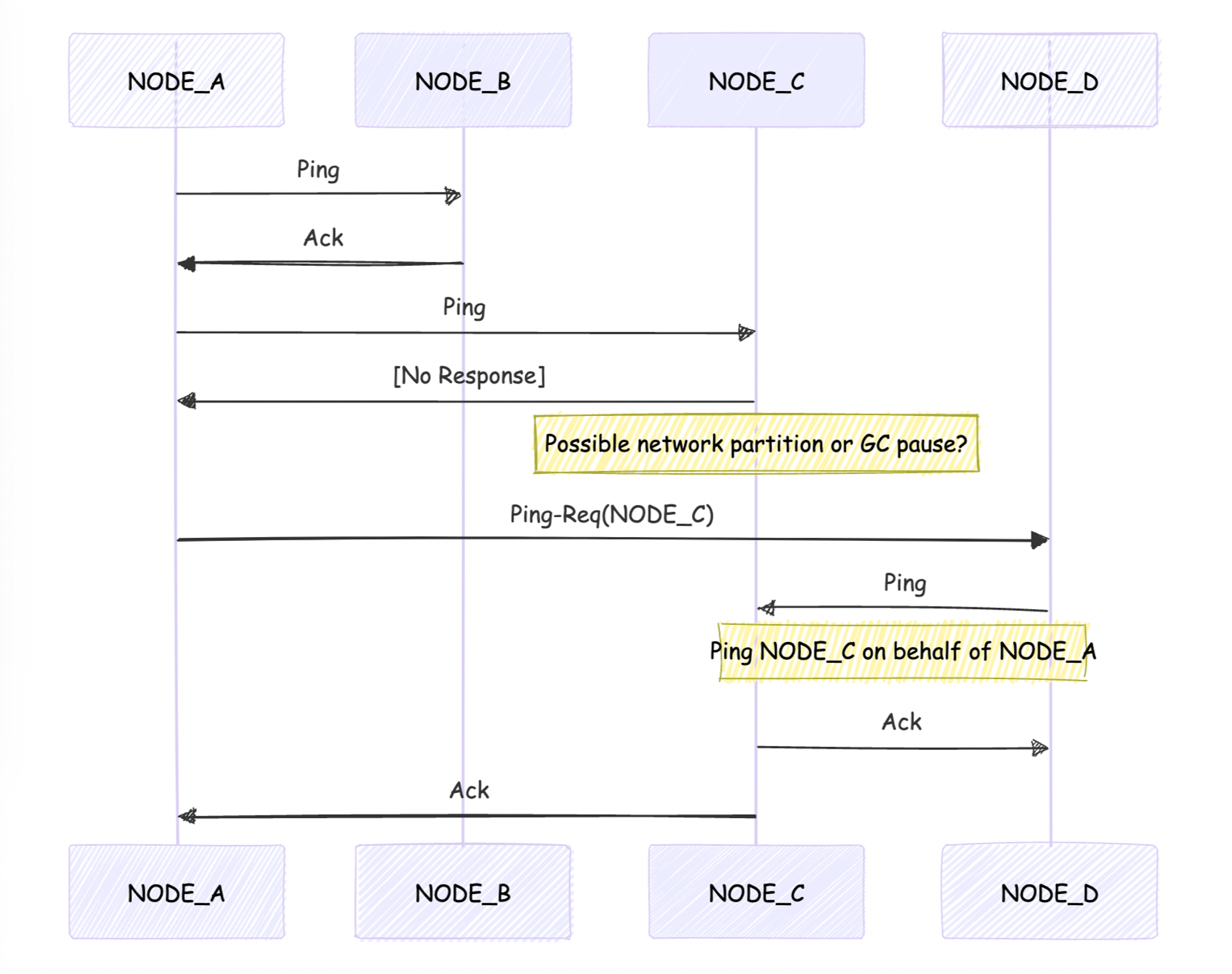
Diagram of how failure detector works
Information Dissemination
The Dissemination Component plays a crucial role in maintaining a consistent view of the network’s membership across all nodes. It is responsible for efficiently propagating information about membership changes and failure suspicions throughout the distributed system.
Key aspects of the Dissemination Component include:
1. Piggybacking: Information is piggybacked onto regular ping messages used by the Failure Detector, rather than sending separate messages. This reduces network overhead and enhances scalability by creating an infection-style dissemination. For example, a PING-ACK from NODE_A to NODE_B can include an update that NODE_C is dead or NODE_E has joined the cluster.
2. Gossip-based Propagation: Each node periodically shares its knowledge about the network’s state with a small, randomly selected subset of other nodes. This epidemic-style approach ensures information eventually reaches all nodes in the system.
3. Types of Information Disseminated:
- Join Events: New nodes entering the network.
- Leave Events: Nodes voluntarily leaving the network.
- Failure Suspicions: Suspected node failures.
- Failure Confirmations: Confirmed node failures.
Suspicions node within cluster (SWIM+Inf.+Susp.)
The concept of a "suspected node within the cluster" is one of SWIM’s key ideas to reduce false positives in failure detection. This mechanism, often referred to as SWIM+Inf.+Susp. (SWIM with Infection and Suspicion), introduces an intermediate state between “alive” and “failed” for nodes in the cluster.
In this enhanced version of SWIM, when a node fails to respond to a ping, it isn’t immediately marked as “failed.” Instead, it enters a “suspect” state. This suspected status is then disseminated to other nodes in the cluster using SWIM’s infection-style (gossip) approach. During a configurable timeout period, other nodes attempt to ping the suspected node, providing multiple chances for the node to respond and defend itself before being declared failed.
This suspicion mechanism significantly reduces false positives that can occur due to temporary network issues, GC, or momentary node overloads. By allowing a grace period and involving multiple nodes in the failure detection process, SWIM+Inf.+Susp reduces the chance of incorrect failure declarations.
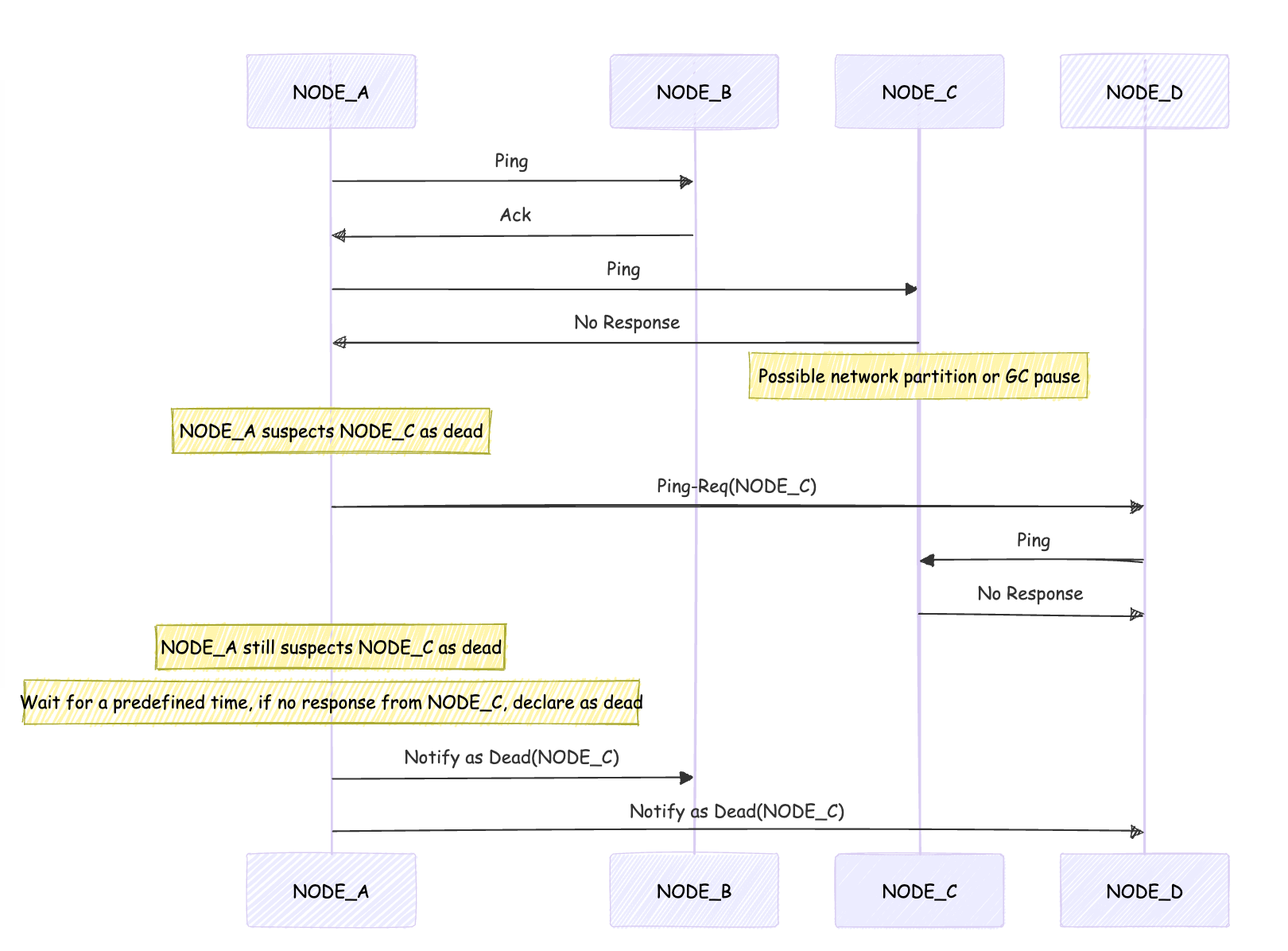
Suspicions node within cluster (SWIM+Inf.+Susp.)
As illustrated in the diagram above, if NODE_C fails to respond within a predetermined timeout period, it’s then confirmed to be dead and this information is disseminated.
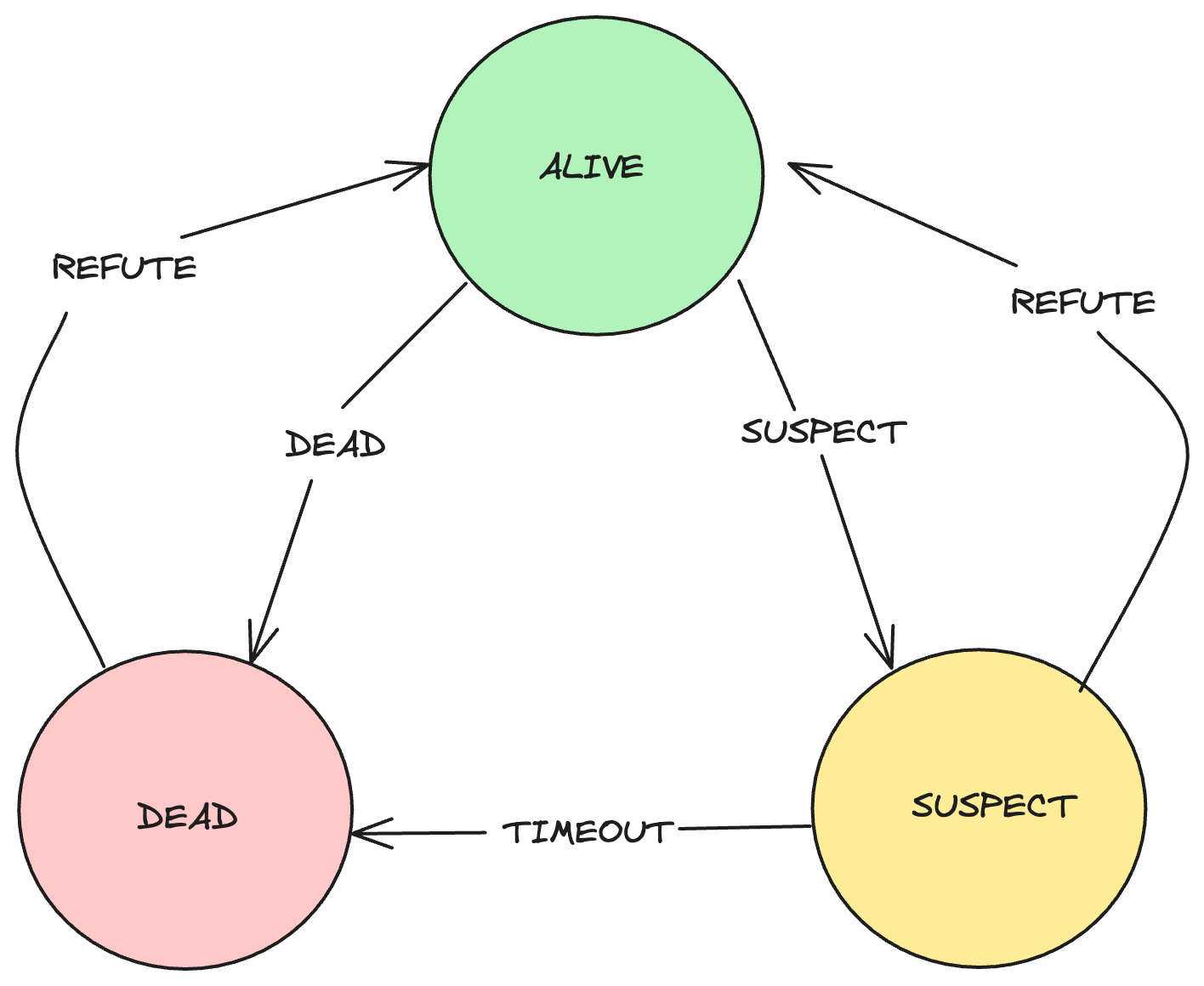
SWIM State FSM:
When a node sends a PING message to another node and does not receive an ACK response, it marks the destination node as SUSPECTED of failure. This suspicion message is then disseminated across the cluster. If the SUSPECTED node is still ALIVE, it can REFUTE this state. If it does not REFUTE the suspicion within a specified timeframe, its peers will move it to a DEAD state.
Let's talk about Incarnation Numbers:
Incarnation Numbers are a cornerstone of the SWIM protocol, providing a mechanism for logical time and state management. These numbers share similarities with Lamport clocks but have a distinct characteristic: they always reset to zero upon system restart.
Key features of Incarnation Numbers:
- Function as logical time for state updates.
- Maintained globally across the system on each node’s local membership list.
- Incremented exclusively by the node itself and no one else.
Example:
Let’s consider a scenario where a node has been marked as suspected by its peers. This suspected node then receives an update notifying it of being suspected of failure. In response to this notification, the node will take action to refute the suspicion. It does this by incrementing its incarnation number. This increment is crucial because it forces the node’s peers to update their state when they receive an update with a higher incarnation number than what they have stored locally. By increasing its incarnation number and broadcasting this new information, the suspected node effectively overrides the previous suspicion. This mechanism ensures that false positive suspicions can be quickly corrected, maintaining an accurate view of the cluster’s membership and providing an opportunity for the node to defend itself against false positives.
In Summary, SWIM provides a membership substrate that:
- Imposes a constant message load per group member.
- Detects a process failure in (expected) constant time at some non-faulty process in the group.
- Provides a deterministic bound (as a function of group size) on the local time that a non-faulty process takes to detect failure of another process.
- Propagates membership updates, including information about failures, in infection-style (gossip-style or epidemic-style); the dissemination latency in the group grows slowly (logarithmically) with the number of members.
- Provides a mechanism to reduce the rate of false positives by “suspecting” a process before “declaring” it as failed within the group.
SWIM Is Not Without Problems:
- Packet Loss: In network communications, packets can be lost due to various factors such as network congestion or hardware failures. The use of UDP makes this issue even more significant. This can lead to incomplete or delayed information propagation across the system.
- Packets Delivered Out-of-Order: Network latency and routing can cause packets to arrive at their destination in a different order than they were sent. This can potentially lead to inconsistent views of the system state among different nodes.
- Gossip is Randomized: The gossip-based dissemination in SWIM relies on randomization for spreading information. While this approach helps with scalability, it can sometimes result in uneven or slower information propagation.
SWIM Implementation for Gossipod In a Nutshell
Gossipod employs three types of messages: PING, PING-REQ, andBROADCAST (which includes JOIN, LEAVE, SUSPECT, ALIVE, and CONFIRM subtypes). The PING and PING-REQ messages are central to the system's failure detection mechanism based on SWIM, facilitating constant state exchange by piggybacking information dissemination on this process. When a state change occurs, either through voluntary requests or regular failure detection, the system uses BROADCAST for random dissemination of this information. Each node in the network maintains an incarnation number, starting at zero, which can only be incremented by the node itself. This number is crucial for managing the node's state in other nodes' local membership lists and serves as a means to refute suspicions (SWIM+Inf.+Susp.) from other nodes. This design allows Gossipod to achieve efficient and resilient distributed state management and failure detection in a distributed or decentralized network.

SWIM Implementation for Gossipod In a Nutshell
Example of SWIM Implementation for Gossipod:
Two-Node SWIM Cluster with Application-Specific Messaging
This example illustrates the behavior of two nodes in a SWIM cluster, demonstrating both the protocol’s membership management and application-specific communication.
-
Node A: Cluster Initialization
- Node A starts and initializes the SWIM protocol.
- It creates a cluster with itself as the only member.
- Node A begins its periodic protocol execution, ready to detect and incorporate new members.
-
Node B: Joining the Cluster
- Node B starts and attempts to join the cluster.
- It contacts Node A using SWIM’s join mechanism.
- Node A detects Node B and updates its membership list.
- Both nodes now have a consistent view of the cluster membership.
-
Application-Specific Communication:
With the SWIM protocol managing membership, the nodes begin application-specific messaging:
-
Node A sends a “ping” message to Node B:
Node A -> Node B: {type: "ping", value: 1} -
Node B receives the ping and responds with a “pong”:
Node B -> Node A: {type: "pong", value: 2} -
This ping-pong exchange continues, with each node incrementing the value:
Node A -> Node B: {type: "ping", value: 3} Node B -> Node A: {type: "pong", value: 4}
-
-
Ongoing Operations
- SWIM continues to manage cluster membership in the background.
- Nodes periodically exchange protocol messages to detect failures and membership changes.
- Application-specific ping-pong messages are sent independently of SWIM’s protocol messages.
Let’s Write Some Code in Rust:
Node A:
You can find the full code for Node A implementation here.
// Code for Node A (ping_node.rs)
use std::net::SocketAddr;
use std::{net::IpAddr};
use std::sync::Arc;
use std::time::Duration;
use anyhow::{Context, Result};
use async_trait::async_trait;
use gossipod::{config::{GossipodConfigBuilder, NetworkType}, DispatchEventHandler, Gossipod, Node, NodeMetadata};
use log::*;
use serde::{Deserialize, Serialize};
use tokio::sync::mpsc::{self};
use tokio::time;
use clap::Parser;
const NODE_NAME: &str = "NODE_1";
const BIND_PORT: u16 = 7948;
const TICK_INTERVAL: Duration = Duration::from_secs(3);
struct SwimNode {
gossipod: Arc<Gossipod>,
receiver: mpsc::Receiver<Vec<u8>>,
config: gossipod::config::GossipodConfig,
}
#[derive(Clone, Debug, Serialize, Deserialize)]
struct Message {
key: String,
value: u64,
}
struct EventHandler{
sender: mpsc::Sender<Vec<u8>>,
}
impl EventHandler {
fn new(sender: mpsc::Sender<Vec<u8>>) -> Self{
Self { sender }
}
}
#[async_trait]
impl<M: NodeMetadata> DispatchEventHandler<M> for EventHandler {
async fn notify_dead(&self, node: &Node<M>) -> Result<()> {
info!("Node {} detected as dead", node.name);
Ok(())
}
async fn notify_leave(&self, node: &Node<M>) -> Result<()> {
info!("Node {} is leaving the cluster", node.name);
Ok(())
}
async fn notify_join(&self, node: &Node<M>) -> Result<()> {
info!("Node {} has joined the cluster", node.name);
Ok(())
}
async fn notify_message(&self, from: SocketAddr, message: Vec<u8>) -> Result<()> {
info!("Received message from {}: {:?}", from, message);
self.sender.send(message).await?;
Ok(())
}
}
impl SwimNode {
async fn new(args: &Args) -> Result<Self> {
let config = GossipodConfigBuilder::new()
.name(&args.name)
.port
(args.port)
.addr(args.ip.parse::<IpAddr>().expect("Invalid IP address"))
.probing_interval(Duration::from_secs(5))
.ack_timeout(Duration::from_millis(500))
.indirect_ack_timeout(Duration::from_secs(1))
.suspicious_timeout(Duration::from_secs(5))
.network_type(NetworkType::Local)
.build()
.await?;
let (sender, receiver) = mpsc::channel(1000);
let dispatch_event_handler = EventHandler::new(sender);
let gossipod = Gossipod::with_event_handler(config.clone(), Arc::new(dispatch_event_handler) )
.await
.context("Failed to initialize Gossipod with custom metadata")?;
Ok(SwimNode {
gossipod: gossipod.into(),
receiver,
config,
})
}
async fn start(&self) -> Result<()> {
let gossipod_clone = self.gossipod.clone();
tokio::spawn(async move {
if let Err(e) = gossipod_clone.start().await {
error!("[ERR] Error starting Gossipod: {:?}", e);
}
});
while !self.gossipod.is_running().await {
time::sleep(Duration::from_millis(100)).await;
}
let local_node = self.gossipod.get_local_node().await?;
info!("Local node: {}:{}", local_node.ip_addr, local_node.port);
Ok(())
}
async fn run(&mut self) -> Result<()> {
let mut ticker = time::interval(TICK_INTERVAL);
let mut counter: u64 = 0;
loop {
tokio::select! {
_ = ticker.tick() => {
self.send_ping_to_all(&mut counter).await;
}
Some(data) = self.receiver.recv() => {
self.handle_incoming_message(data, &mut counter).await;
}
_ = tokio::signal::ctrl_c() => {
info!("Signal received, stopping Gossipod...");
self.gossipod.stop().await?;
return Ok(());
}
}
}
}
async fn send_ping_to_all(&self, counter: &mut u64) {
let msg = Message {
key: "ping".to_string(),
value: *counter,
};
for node in self.gossipod.members().await.unwrap_or_default() {
if node.name == self.config.name() {
continue; // skip self
}
let target = node.socket_addr().unwrap();
info!("Sending to {}: key={} value={} target={}", node.name, msg.key, msg.value, target);
if let Err(e) = self.gossipod.send(target, &bincode::serialize(&msg).unwrap()).await {
error!("Failed to send message to {}: {}", node.name, e);
}
}
}
async fn handle_incoming_message(&self, data: Vec<u8>, counter: &mut u64) {
let msg: Message = match bincode::deserialize(&data) {
Ok(m) => m,
Err(e) => {
error!("Failed to deserialize message: {}", e);
return;
}
};
info!("Received: key={} value={}", msg.key, msg.value);
*counter = msg.value + 1;
}
}
#[derive(Parser, Debug)]
#[command(author, version, about, long_about = None)]
struct Args {
#[arg(long, default_value = NODE_NAME)]
name: String,
#[arg(long, default_value_t = BIND_PORT)]
port: u16,
#[arg(long, default_value = "127.0.0.1")]
ip: String,
#[arg(long)]
join_addr: Option<String>,
}
#[tokio::main]
async fn main() -> Result<()> {
let args = Args::parse();
let mut node = SwimNode::new(&args).await?;
node.start().await?;
node.run().await?;
info!("Node stopped. Goodbye!");
Ok(())
}
Run the command:
cargo run --example ping_node -- --name=NODE_A --port=7948Example logs:
[2024-08-05T11:18:24Z INFO ping_node] Sending to NODE_B: key=ping value=0 target=127.0.0.1:7947
[2024-08-05T11:18:24Z INFO gossipod::transport] [RECV] Incoming TCP connection from: 127.0.0.1:54208
[2024-08-05T11:18:24Z INFO ping_node] Received: key=pong value=1
...Node B:
You can find the full code for Node B implementation here.
// Code for Node B (pong_node.rs)
use std::net::{IpAddr, SocketAddr};
use std::sync::Arc;
use std::time::Duration;
use anyhow::{Context, Result};
use async_trait::async_trait;
use gossipod::{DispatchEventHandler, Node, NodeMetadata};
use gossipod::{config::{GossipodConfigBuilder, NetworkType}, Gossipod};
use log::*;
use serde::{Deserialize, Serialize};
use tokio::sync::mpsc::{self};
use tokio::time;
use clap::Parser;
const NODE_NAME: &str = "NODE_B";
const BIND_PORT: u16 = 7947;
#[derive(Parser, Debug)]
#[command(author, version, about, long_about = None)]
struct Args {
#[arg(long, default_value = NODE_NAME)]
name: String,
#[arg(long, default_value_t = BIND_PORT)]
port: u16,
#[arg(long, default_value = "127.0.0.1")]
ip: String,
#[arg(long)]
join_addr: Option<String>,
}
#[derive(Clone, Debug, Serialize, Deserialize)]
struct Message {
key: String,
value: u64,
}
struct SwimNode {
gossipod: Arc<Gossipod>,
receiver: mpsc::Receiver<Vec<u8>>,
config: gossipod::config::GossipodConfig,
}
struct EventHandler{
sender: mpsc::Sender<Vec<u8>>,
}
impl EventHandler {
fn new(sender: mpsc::Sender<Vec<u8>>) -> Self{
Self { sender }
}
}
#[async_trait]
impl<M: NodeMetadata> DispatchEventHandler<M> for EventHandler {
async fn notify_dead(&self, node: &Node<M>) -> Result<()> {
info!("Node {} detected as dead", node.name);
Ok(())
}
async fn notify_leave(&self, node: &Node<M>) -> Result<()> {
info!("Node {} is leaving the cluster", node.name);
Ok(())
}
async fn notify_join(&self, node: &Node<M>) -> Result<()> {
info!("Node {} has joined the cluster", node.name);
Ok(())
}
async fn notify_message(&self, from: SocketAddr, message: Vec<u8>) -> Result<()> {
info!("Received message from {}: {:?}", from, message);
self.sender.send(message).await?;
Ok(())
}
}
impl SwimNode {
async fn new(args: &Args) -> Result<Self> {
let config = GossipodConfigBuilder::new()
.name(&args.name)
.port(args.port)
.addr(args.ip.parse::<IpAddr>().expect("Invalid IP address"))
.probing_interval(Duration::from_secs(5))
.ack_timeout(Duration::from_millis(3_000))
.indirect_ack_timeout(Duration::from_secs(1))
.suspicious_timeout(Duration::from_secs(5))
.network_type(NetworkType::Local)
.build()
.await?;
let (sender, receiver) = mpsc::channel(1000);
let dispatch_event_handler = EventHandler::new(sender);
let gossipod = Gossipod::with_event_handler(config.clone(), Arc::new(dispatch_event_handler) )
.await
.context("Failed to initialize Gossipod with custom metadata")?;
Ok(SwimNode {
gossipod: gossipod.into(),
receiver,
config,
})
}
async fn start(&self) -> Result<()> {
let gossipod_clone = self.gossipod.clone();
tokio::spawn(async move {
if let Err(e) = gossipod_clone.start().await {
error!("[ERR] Error starting Gossipod: {:?}", e);
}
});
while !self.gossipod.is_running().await {
time::sleep(Duration::from_millis(100)).await;
}
let local_node = self.gossipod.get_local_node().await?;
info!("Local node: {}:{}", local_node.ip_addr, local_node.port);
Ok(())
}
async fn run(&mut self) -> Result<()> {
loop {
tokio::select! {
Some(msg) = self.receiver.recv() => {
self.handle_incoming_message(msg).await?;
}
_ = tokio::signal::ctrl_c() => {
info!("Signal received, stopping Gossipod...");
self.gossipod.stop().await?;
return Ok(());
}
}
}
}
async fn handle_incoming_message(&self, data: Vec<u8>) -> Result<()> {
let msg: Message = bincode::deserialize(&data)
.map_err(|e| anyhow::anyhow!("Failed to
deserialize msg from bytes: {}", e))?;
info!("Received: key={} value={}", msg.key, msg.value);
if msg.key == "ping" {
self.send_pong_to_all(msg.value).await?;
}
Ok(())
}
async fn send_pong_to_all(&self, value: u64) -> Result<()> {
let msg = Message {
key: "pong".to_string(),
value: value + 1,
};
for node in self.gossipod.members().await? {
if node.name == self.config.name() {
continue; // skip self
}
info!("Sending to {}: key={} value={}", node.name, msg.key, msg.value);
self.gossipod.send(node.socket_addr()?, &bincode::serialize(&msg)?).await?;
}
Ok(())
}
}
#[tokio::main]
async fn main() -> Result<()> {
let args = Args::parse();
let mut node = SwimNode::new(&args).await?;
node.start().await?;
if let Some(join_addr) = args.join_addr {
match join_addr.parse::<SocketAddr>() {
Ok(addr) => {
info!("Attempting to join {}", addr);
if let Err(e) = node.gossipod.join(addr).await {
error!("Failed to join {}: {:?}", addr, e);
} else {
info!("Successfully joined {}", addr);
}
},
Err(e) => error!("Invalid join address {}: {:?}", join_addr, e),
}
} else {
info!("No join address specified. Running as a standalone node.");
}
node.run().await?;
info!("[PROCESS] Gossipod has been stopped");
Ok(())
}
Run the command:
cargo run --example pong_node -- --name=NODE_B --port=7947 --join-addr=127.0.0.1:7948Example logs:
[2024-08-05T11:18:24Z INFO gossipod::transport] [RECV] Incoming TCP connection from: 127.0.0.1:54207
[2024-08-05T11:18:24Z INFO pong_node] Received: key=ping value=0
...Testing
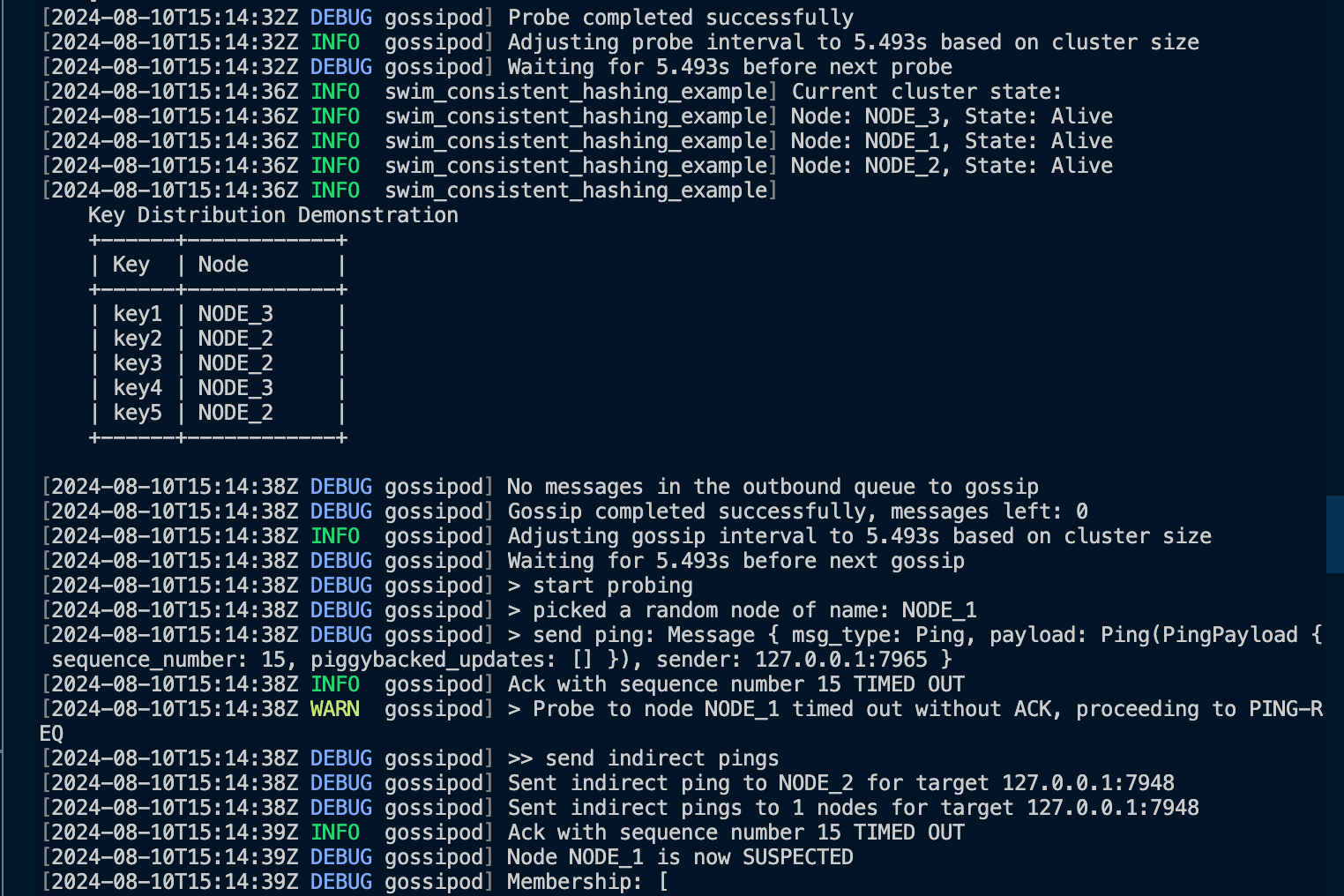
Testing is done using consistent hashing for distributing keys across nodes.
More examples are available at https://github.com/TheDhejavu/gossipod-examples.